Project information
- Category: NLP, Classification
- Source Data: Download
Project Details
What is fake news?
Fake news use pieces of news that may be hoaxes and is generally spread through social media and other online media. This is often done to further or impose certain ideas and is often achieved with political agendas. Such news items may contain false and/or exaggerated claims, and may end up being virilized by algorithms, and users may end up in a filter bubble.
What is a TfidfVectorizer?
TF-IDF stands for term frequency- inverse document frequency.It is a measurement widely used in information retrieval (IR) and machine learning. It can quantify the importance or relevance of string representation in a sentence among a collection of sentences.
• TF (Term Frequency): The number of times a word appears in a document is its Term Frequency. A higher value means a term appears more often than others, and so, the document is a good match when the term is part of the search terms.
• IDF (Inverse Document Frequency): Words that occur many times a document, but also occur many times in many others, may be irrelevant. IDF is a measure of how significant a term is in the entire corpus.
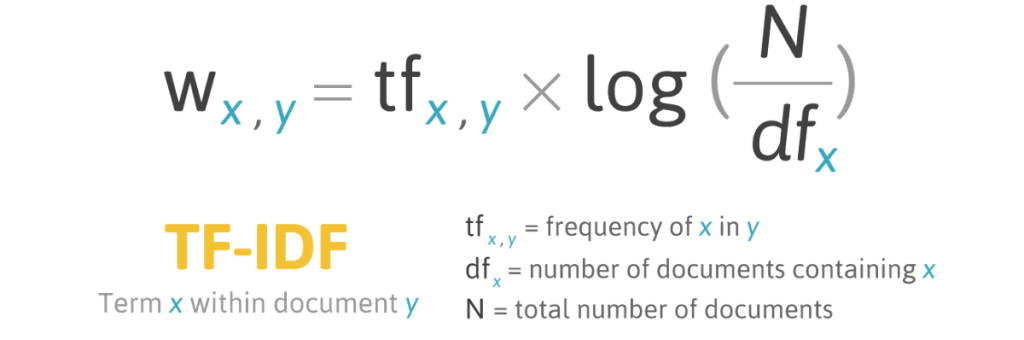
As the dataset has labeled the variable, it is supervised machine learning. Supervised machine learning is a type of machine learning that are trained on well-labeled training data. Labeled data means that training data is already tagged with correct output.
In this project, I will solve the problem using PassiveAggressive classifier, logistical regression and svc and compare their accuracy as it is a supervised algorithm which relies on training data to learn and improve their accuracy over time. Once these learning algorithms are fine-tuned for accuracy, they are powerful tools in classification and clustering data.
Python Packages:
Roadmap:
Step 1:
Import packages:
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import PassiveAggressiveClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import LinearSVC from sklearn.metrics import accuracy_score, confusion_matrix
#Read the data file_path=r'C:\Users\shang\Desktop\ML\data\news.csv' df=pd.read_csv(file_path) print(df.head())

X=df['text'] Y=df.label print(Y.head())
Step2: Split a dataset into training and testing datasets
# Split the dataset X_train,X_test,y_train,y_test=train_test_split(X, Y, test_size=0.2, random_state=42)
Step3: Train the model
# Initialize a TfidfVectorizer tfidf_vectorizer=TfidfVectorizer(stop_words='english', max_df=0.7) # Fit and transform train set, transform test set converted_train=tfidf_vectorizer.fit_transform(X_train) converted_test=tfidf_vectorizer.transform(X_test)
# Train different algorithms and compare them using accuracy
models = []
models.append(('LogisticRegression', LogisticRegression()))
models.append(('LinearSVC', LinearSVC()))
models.append(('PassiveAggressiveClassifier', PassiveAggressiveClassifier()))
Step 4: Model Evaluation
# evaluate each model in turn
names = []
scoring = 'accuracy'
for name, model in models:
model=model.fit(converted_train, y_train)
pred = model.predict(converted_test)
score=accuracy_score(y_test,pred)
# DataFlair - Build confusion matrix
matrix = confusion_matrix(y_test, pred,labels=['FAKE','REAL'])
print(f'Accuracy: {round(score*100,2)}%')
print('confusion matrix:'+name)
print(matrix)
